A company has a typical RAG-enabled, customer-facing chatbot on its website.
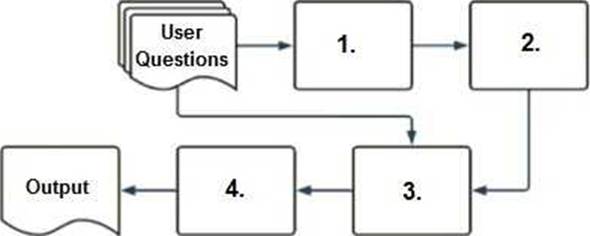
Select the correct sequence of components a user's questions will go through before the final output is returned. Use the diagram above for reference.
A. 1. embedding model, 2. vector search, 3. context-augmented prompt, 4. response-generating LLM
B. 1. context-augmented prompt, 2. vector search, 3. embedding model, 4. response-generating LLM
C. 1. response-generating LLM, 2. vector search, 3. context-augmented prompt, 4. embedding model
D. 1. response-generating LLM, 2. context-augmented prompt, 3. vector search, 4. embedding model
Explanation:
To understand how a typical RAG-enabled customer-facing chatbot processes a user's question, let’s go through the correct sequence as depicted in the diagram and explained in option A:
Embedding Model (1):
The first step involves the user's question being processed through an embedding model. This model converts the text into a vector format that numerically represents the text. This step is essential for allowing the subsequent vector search to operate effectively.
Vector Search (2):
The vectors generated by the embedding model are then used in a vector search mechanism. This search identifies the most relevant documents or previously answered questions that are stored in a vector format in a database.
Context-Augmented Prompt (3):
The information retrieved from the vector search is used to create a context-augmented prompt. This step involves enhancing the basic user query with additional relevant information gathered to ensure the generated response is as accurate and informative as possible.
Response-Generating LLM (4):
Finally, the context-augmented prompt is fed into a response-generating large language model (LLM). This LLM uses the prompt to generate a coherent and contextually appropriate answer, which is then delivered as the final output to the user.
Why Other Options Are Less Suitable:
B, C, D: These options suggest incorrect sequences that do not align with how a RAG system typically processes queries. They misplace the role of embedding models, vector search, and response generation in an order that would not facilitate effective information retrieval and response generation.
Thus, the correct sequence is embedding model, vector search, context-augmented prompt, response-generating LLM, which is option A.
