A. To configure the cluster to meet the requirements of the infosec team, you need to do the following steps:
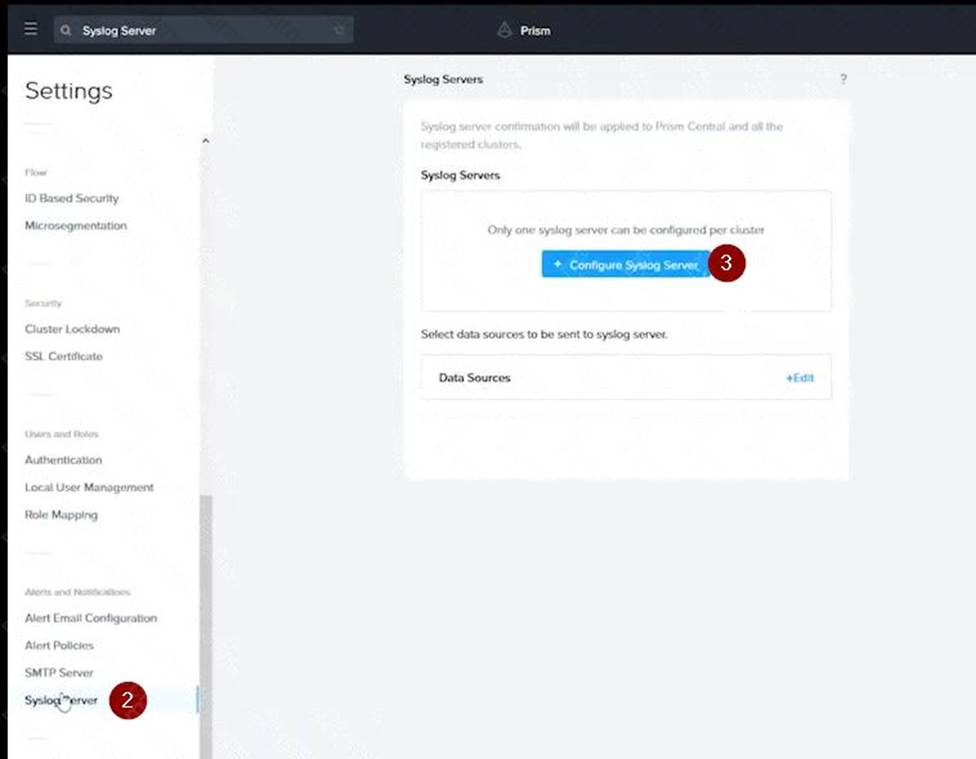
Log in to Prism Central and go to Network > Syslog Servers > Configure Syslog Server. Enter Corp_syslog as
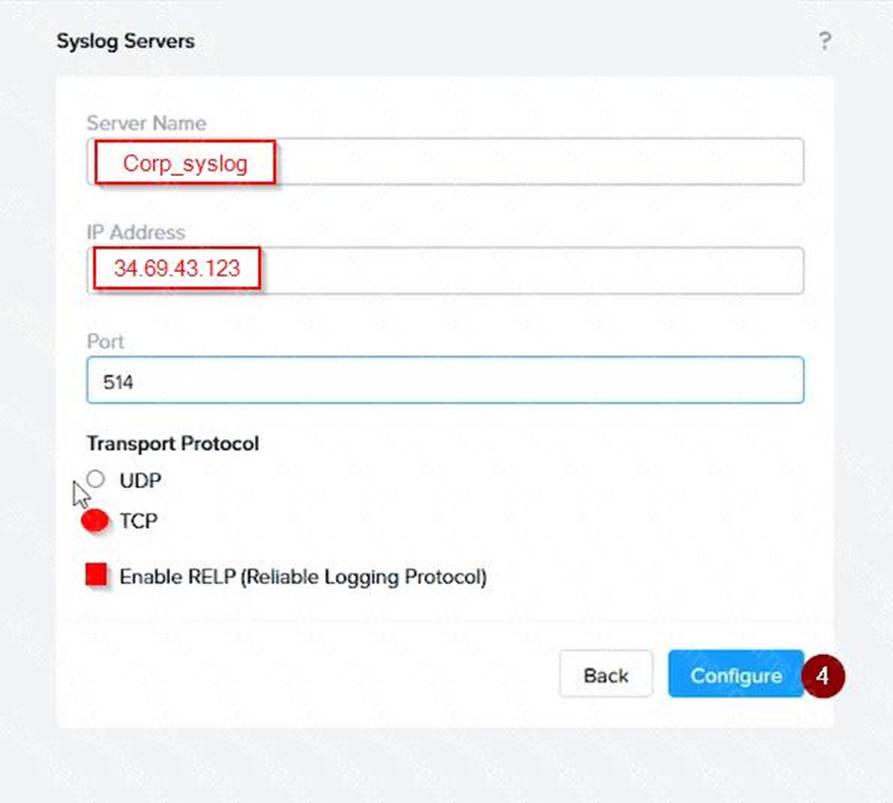
the Server Name, 34.69.43.123 as the IP Address, and 514 as the Port. Select TCP as the Transport Protocol and enable RELP (Reliable Logging Protocol). This will create a syslog server with the highest reliability possible.
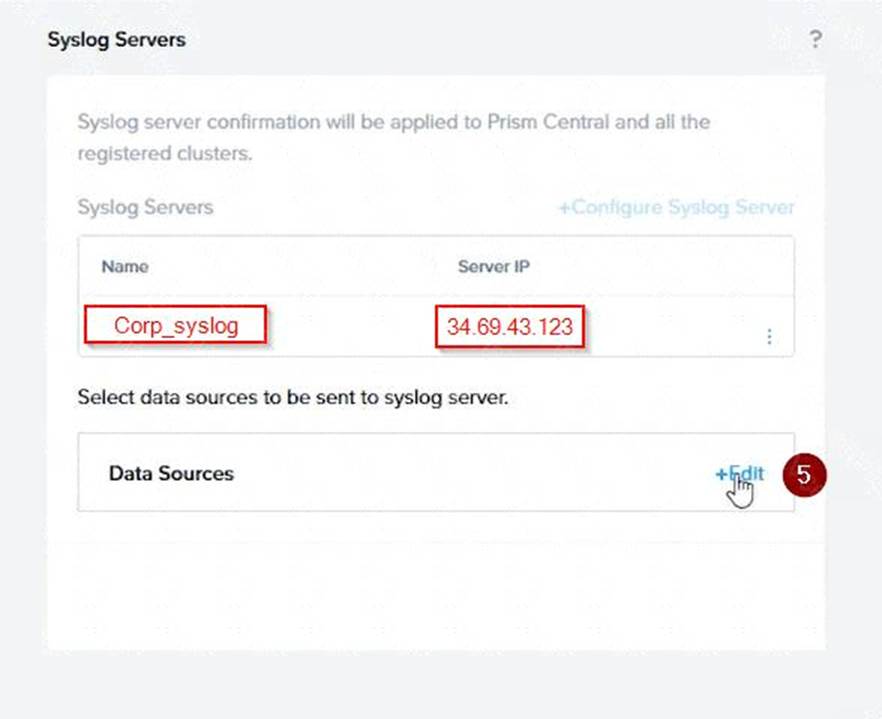
Click Edit against Data Sources and select Cluster B as the cluster. Select API Requests and Replication as the data sources and set the log level to CRITICAL for both of them. This will enable audit logs for API requests and replication capabilities for the top 4 severity levels (EMERGENCY, ALERT, CRITICAL, and ERROR) and push them to the syslog server. Click Save.
Repeat step 2 for any other clusters that you want to configure with the same requirements.
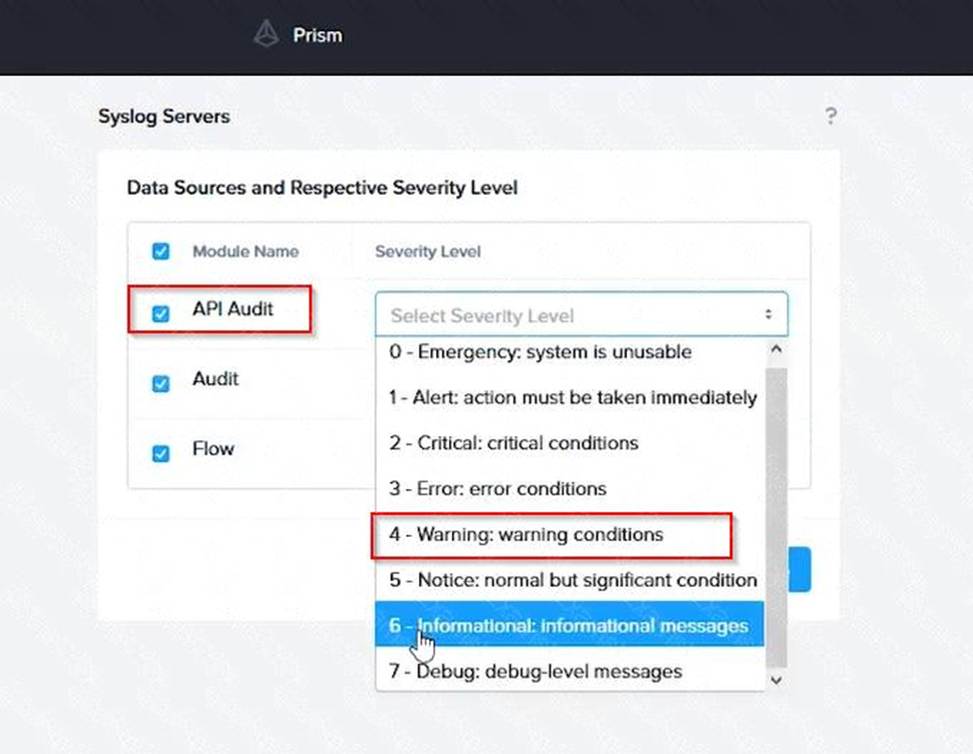
To configure the Nutanix clusters to enable audit logs for API Requests and replication capabilities, and push them to the syslog system with the highest reliability possible, you can follow these steps:
Log in to the Nutanix Prism web console using your administrator credentials.
Navigate to the "Settings" section or the configuration settings interface within Prism.
Locate the "Syslog Configuration" or "Logging" option and click on it.
Configure the syslog settings as follows:
Syslog Name: Enter "Corp_syslog" as the name for the syslog configuration.
Syslog IP: Set the IP address to "34.69.43.123", which is the IP address of the syslog system.
Port: Set the port to "514", which is the default port for syslog.
Enable the option for highest reliability or persistent logging, if available. This ensures that logs are sent reliably and not lost in case of network interruptions.
Save the syslog configuration.
Enable Audit Logs for API Requests:
In the Nutanix Prism web console, navigate to the "Cluster" section or the cluster management interface.
Select the desired cluster where you want to enable audit logs.
Locate the "Audit Configuration" or "Security Configuration" option and click on it.
Look for the settings related to audit logs and API requests. Enable the audit logging feature and select the top 4 severity levels to be logged.
Save the audit configuration.
Enable Audit Logs for Replication Capabilities:
In the Nutanix Prism web console, navigate to the "Cluster" section or the cluster management interface.
Select the desired cluster where you want to enable audit logs.
Locate the "Audit Configuration" or "Security Configuration" option and click on it.
Look for the settings related to audit logs and replication capabilities. Enable the audit logging feature and select the top 4 severity levels to be logged.
Save the audit configuration.
After completing these steps, the Nutanix clusters will be configured to enable audit logs for API Requests and replication capabilities. The logs will be sent to the specified syslog system with the highest reliability possible.
ncli
<ncli> rsyslog-config set-status enable=false
<ncli> rsyslog-config add-server name=Corp_Syslog ip-address=34.69.43.123 port=514 network-protocol=tdp relp-enabled=false
<ncli> rsyslog-config add-module server-name= Corp_Syslog module-name=APLOS level=INFO
<ncli> rsyslog-config add-module server-name= Corp_Syslog module-name=CEREBRO level=INFO
<ncli> rsyslog-config set-status enable=true
https://portal.nutanix.com/page/documents/kbs/details?targetId=kA00e0000009CEECA2
